High-enrolment university courses often rely on weekly reflective writing tasks. While pedagogically valuable, they create a significant marking burden that often results in generic or delayed feedback.
This project evaluated the viability of using Large Language Models (LLMs) to grade student submissions within the RiPPLE platform. The goal was to determine if AI could match the nuance and grade distribution of human course coordinators.
The Goal
We needed to automate the grading for two types of student work: Resource Creation and Peer Moderation. The objective was to build a system that could ingest raw course data, synthesize grades from an assessment rubric, and produce a grade distribution that aligned with the Course Coordinator’s standards.
Methodology
I engineered a Python pipeline to process student submissions through the Anthropic API. The core of the solution was a dynamic prompting system that injected the specific assessment rubric and context into the model for each unique submission type.
To test cost-efficiency versus accuracy, we benchmarked two models:
- Claude Haiku: A lightweight, faster, and cheaper model.
- Claude Sonnet: A larger, “smarter” model with higher reasoning capabilities.
Key Findings
We compared the AI-generated grades against the historical mean of human markers. The results highlighted a significant “Intelligence Gap” between the two models.
1. The “Laziness” of Lightweight Models (Haiku)
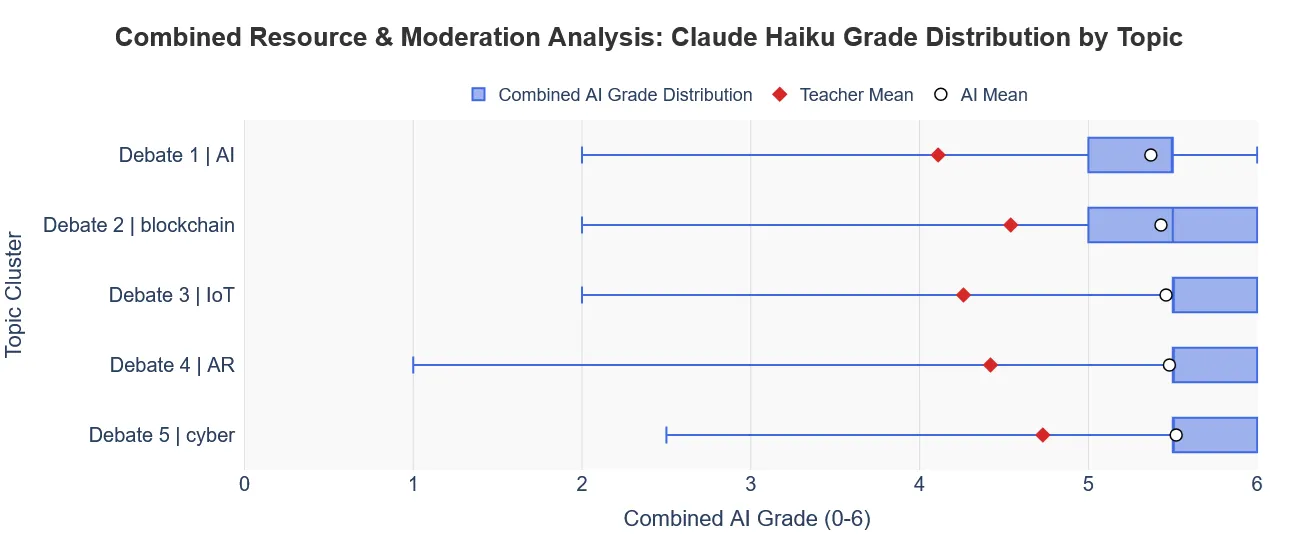
As seen above, Claude Haiku failed to discriminate quality, trending toward a “ceiling effect” where almost every student received full marks. This demonstrated that lightweight models lacked the reasoning required to apply a complex rubric.
2. The Nuance of SOTA Models (Sonnet)
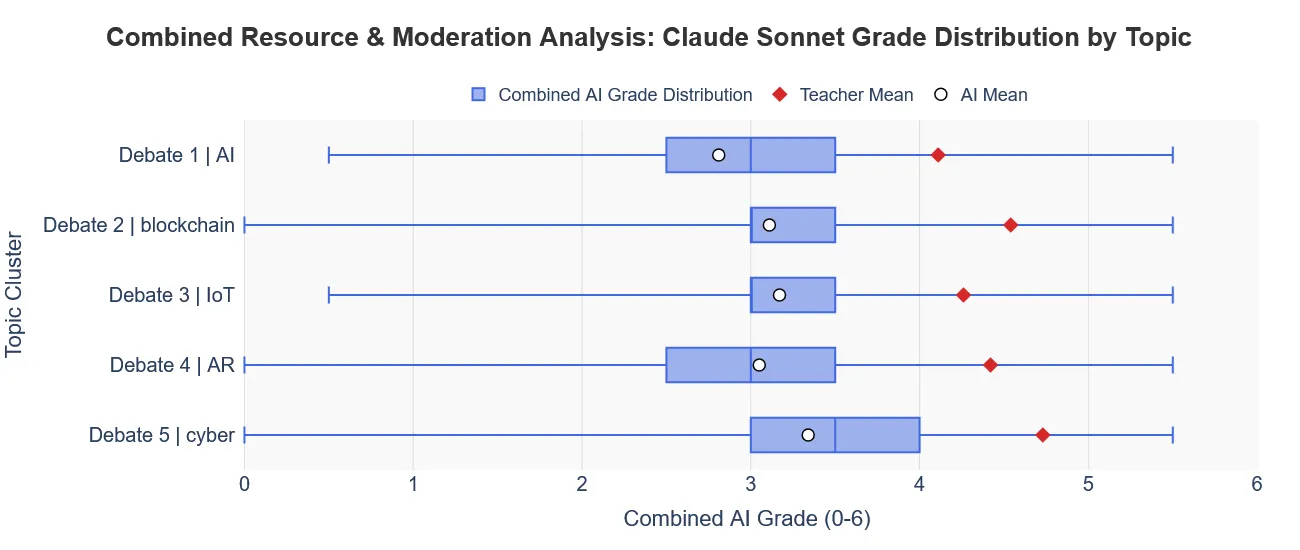
Claude Sonnet demonstrated meaningful differentiation, by producing a clear spread of grades. It evaluates submissions on a spectrum of quality, effectively distinguishing between average and exceptional work.
3. The “Human Context” Factor
An interesting anomaly occurred: The human teachers were consistently more lenient than the advanced AI. The Course Coordinator graded forgivingly to encourage engagement, whereas the AI strictly followed the rubric.
Ethical Considerations & Limitations
- Privacy: We ensured that only the content of the submission and the rubric were passed to the model. No student identifiers (names, IDs) were included in the prompt payload to minimize PII leakage.
- The “Vibe” Problem: AI missed the implicit teacher leniency used to encourage student effort. Future iterations would need to explicitly prompt for this “persona.”
Conclusion
This study proved that while AI can grade, “smarter” models are non-negotiable for assessment tasks. The cheaper model (Haiku) was effectively useless for differentiation. Furthermore, for AI to truly replace or augment human marking, the “unwritten rules” of a course (e.g., leniency for effort) must be systematically engineered into the system prompts.
For a comprehensive analysis, please refer to the published Research Chapter.
Tech Stack
- Python (AsyncIO, Pandas): For fault-tolerant data processing and API concurrency.
- Automated Reporting: Programmatic generation of Excel dashboards for visualization.
- Anthropic API: Claude 3.5 Sonnet & Claude 3.0 Haiku.